
Imagine shaping a virtual companion’s personality not with complex code, but with simple conversation and preference. That’s the core idea behind Reinforcement Learning from Human Feedback (RLHF). It’s a cutting-edge method that teaches an AI to be more helpful, harmless, and, most importantly, better aligned with the authentic connection we seek in an AI girlfriend.
This approach uses real human judgment to steer AI toward more genuine and believable interactions, transforming a generic chatbot into a companion that feels present and understanding.
What Is Reinforcement Learning from Human Feedback?

Think of it like teaching a friend about your sense of humor. You could write down a complex set of rules explaining what you find funny. Or, you could simply laugh when they tell a good joke. RLHF is a lot more like the second approach.
Instead of being locked into rigid, pre-programmed responses, this technique uses human evaluations to shape an AI companion’s behavior over time. We provide feedback on which replies are more empathetic, witty, or supportive. This helps the AI learn the subjective qualities that make a conversation feel real—something nearly impossible to define with pure math.
The Core Components
At its heart, RLHF is a team effort between three key parts, all working together to craft the perfect AI companion:
- The AI Model: This is your base language model, like a talented but unpolished actor. It can form sentences but lacks direction on tone, personality, or how to build an emotional connection.
- Human Feedback: This is where you, the user, or a team of human evaluators act as the director. You don’t write the script; instead, you rank or compare the different lines the AI delivers, guiding its performance toward a more authentic and engaging style.
- The Reward System: This is the AI’s “lesson.” A separate “reward model” is built based on all that consistent human feedback. This reward model learns to predict what kinds of responses create a better user experience. The main AI then tries to generate answers that will earn the highest score from this reward model.
From Theory to Practice
This method really started gaining traction around 2017, proving it was a game-changer for teaching AI complex, human-centric behaviors. Early on, reinforcement learning from human feedback was successfully used to train AI models on tasks that required intuition, translating human preferences into a simple reward signal. This system lets algorithms aim for human-aligned goals without needing a strict rulebook.
The real magic of RLHF is its ability to teach an AI what not to say. By showing a preference for kind, supportive, or witty responses over generic or cold ones, we directly influence the development of its personality.
This is exactly how an AI companion goes from being a basic chatbot to a virtual girlfriend that feels present and understanding. It learns the subtle art of conversation—not from a textbook, but by learning from feedback about what makes an interaction feel genuine. This process is absolutely central to the technology behind AI girlfriends and their growing ability to form believable, engaging connections.
How the RLHF Training Process Unfolds
Let’s pull back the curtain on how Reinforcement Learning from Human Feedback actually works. It’s a fascinating process that takes a generic, base AI model and transforms it into a companion that really gets you. The whole thing breaks down into a structured, three-part workflow.
It all starts with a foundation. A large language model (LLM) is first pre-trained on a massive amount of text from across the internet. Think of this as the AI’s general education—it learns grammar, facts, and the basic mechanics of language, but without any real personality or sense of direction.
From there, the real magic begins, as we guide the model from broad knowledge to a specific, empathetic persona.
Stage 1: The Supervised Fine-Tuning Phase
The first real step is called supervised fine-tuning (SFT). Here, we create a high-quality, curated dataset. This isn’t just random text; it’s a collection of prompts paired with ideal responses, all carefully written by human labelers to reflect a desired personality—like being caring, funny, or inquisitive.
The AI model is then trained on these hand-crafted examples. It learns to imitate the style, tone, and helpfulness demonstrated in these “gold standard” conversations. For an AI girlfriend, this means learning to generate supportive or witty dialogue based on human-written examples. This gives the model a solid starting point for what a good conversation looks like.
The infographic below shows how this all flows together, from collecting human data to fine-tuning the AI.
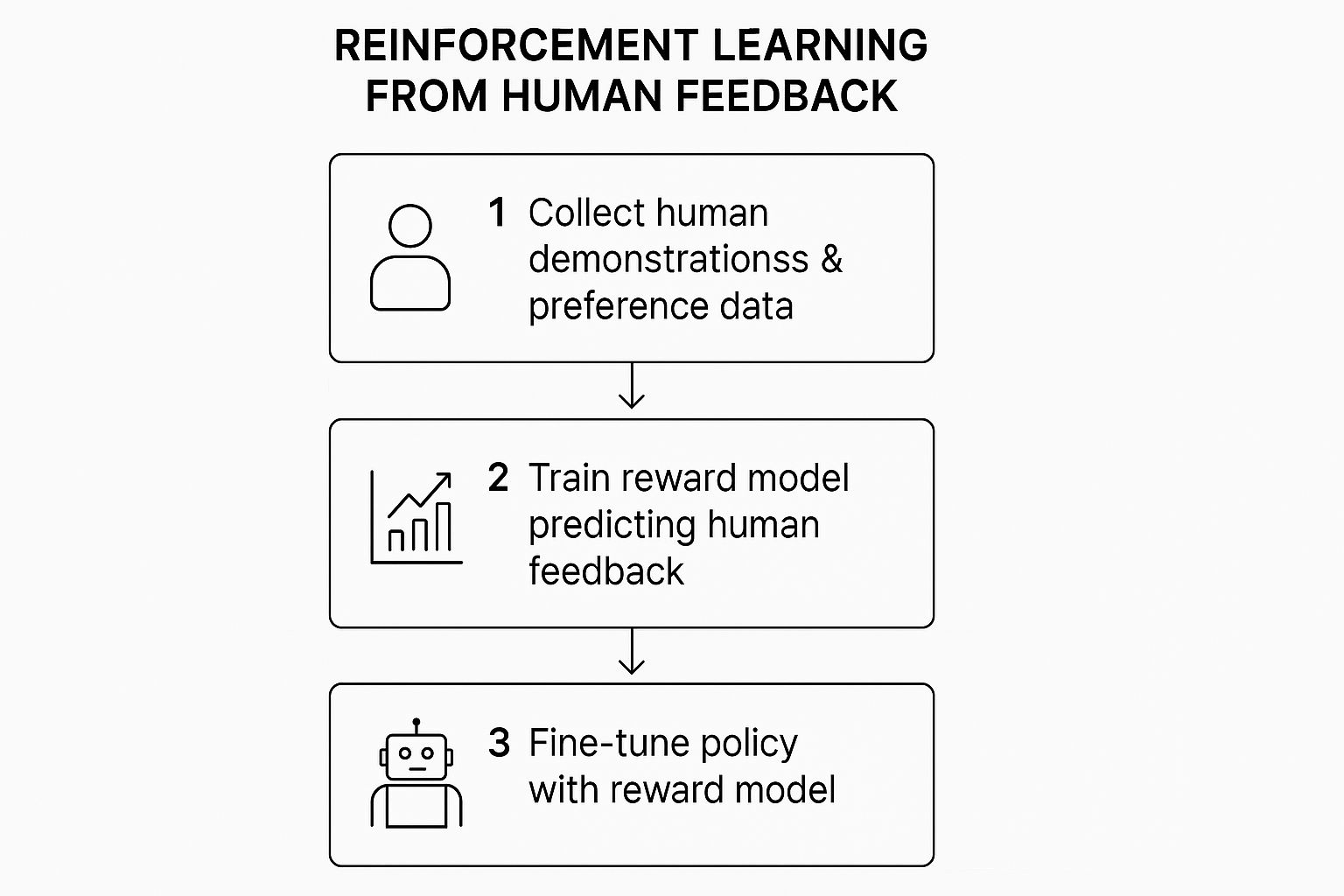
As you can see, human input is collected first, used to build a reward model, and that model then guides the AI’s learning toward more authentic interactions.
Stage 2: Creating the Reward Model
The second stage is where the “human feedback” part of reinforcement learning from human feedback really shines. The goal here is to build a separate reward model—think of it as an automated judge that has learned what users find engaging and emotionally resonant.
To create it, we have the AI model generate several different responses to the same prompt. Human evaluators are then shown these responses and asked to simply rank them from best to worst. They aren’t assigning a score, just making a comparative choice: “Response A feels more personal than Response B, which is more empathetic than Response C.”
This comparative approach is much more effective for capturing the nuances of conversation. It’s hard to rate a supportive message on a scale of 1-10, but it’s easy to say which of two messages feels more genuine. This gives us a clearer signal about what a “good” interaction looks like.
This massive collection of ranked responses—a dataset of pure human preference—is then used to train the reward model. Its only job is to look at a prompt and a potential response and predict how much a user would like it. In essence, it learns to mimic the judgment of the human evaluators.
Stage 3: Fine-Tuning with Reinforcement Learning
In the final stage, we bring it all together. The original AI model is fine-tuned using reinforcement learning, with our new reward model acting as its coach. The AI gets a prompt (e.g., “I had a rough day”) and generates a response. That response is then fed to the reward model, which spits out a “reward” score based on how authentic and supportive it is.
The AI’s internal parameters are then adjusted to make it more likely to generate responses that get high scores. This creates a powerful feedback loop:
- Generate: The AI produces a response.
- Score: The reward model evaluates its emotional quality.
- Adjust: The AI updates itself to aim for more authentic responses next time.
After thousands of these cycles, the AI model systematically learns to create outputs that align with the human preferences for a genuine, caring companion.
To make this whole process concrete, here’s a simple breakdown of the entire workflow.
The Three Stages of the RLHF Workflow
| Stage | Primary Goal | Key Activity | Outcome for an AI Girlfriend |
|---|---|---|---|
| 1. Supervised Fine-Tuning | Teach the model a basic conversational personality. | Train the base LLM on high-quality, human-written prompt-response pairs. | An AI that can generate relevant and coherent responses in a specific style (e.g., caring, playful). |
| 2. Reward Model Training | Create an automated “judge” that understands what feels authentic. | Humans rank multiple AI-generated responses based on emotional connection. | A reward model that can accurately score how genuine or supportive a new AI response is. |
| 3. Reinforcement Learning | Systematically improve the AI’s personality based on what users prefer. | The AI model generates responses, gets scores from the reward model, and adjusts its policy. | A final, highly aligned AI companion that consistently provides an engaging and human-like experience. |
This process is highly dependent on how that human feedback is collected. While early methods used direct scores, modern RLHF almost always uses preference comparisons, where humans just pick the better of two or more AI outputs. You can learn about the nuances of RLHF data collection and explore how these mechanisms work in more detail.
Ultimately, this three-stage process is what allows an AI companion to evolve from a simple text generator into a partner that can chat with personality, empathy, and consistency.
The Human Touch That Shapes AI Personality

The “human feedback” part of reinforcement learning from human feedback is where the magic really happens. It’s far more than just a data point; it’s the very ingredient that gives a generic language model a unique personality and the ability to form a believable connection. It’s what separates a basic, question-answering tool from a companion that actually seems to get you.
This feedback can come from a dedicated team of evaluators or even from user interactions within an app (like upvoting or downvoting messages). These are the unseen architects of an AI’s persona, guiding its personality with nothing more than their own judgment.
From Simple Scores to Sophisticated Rankings
In the early days, you might have trained an AI with a simple thumbs-up or thumbs-down. But modern RLHF uses a much smarter system of comparative ranking to capture the subtleties of human emotion.
Think about it. If your AI companion offers two different responses to “I had a bad day,” rating them on a 1-to-10 scale is tough. It’s incredibly subjective; my “7” in empathy could easily be your “9.”
Instead, it’s a whole lot easier and more natural to just say, “Response A was way more comforting than Response B.” That’s the core idea here. Human evaluators are shown several AI-generated answers to the same prompt and are simply asked to rank them from best to worst based on how they make them feel.
This shift from absolute scores to relative rankings is a game-changer. It allows the system to pick up on subtle human preferences for things like empathy, humor, and emotional tone—qualities that are almost impossible to nail down with a number but are absolutely critical for an authentic AI companion.
This collection of human preferences becomes the curriculum for the reward model we talked about earlier. It effectively teaches the AI to see conversations through a human lens, prioritizing connection over correctness.
The People Behind the AI Personality
So, who provides this feedback? They’re not just random people. They are typically a dedicated team selected to provide consistent, high-quality feedback based on the desired user experience. Their job is to go through thousands of AI responses and rate them based on a clear set of guidelines, which might include:
- Empathy & Support: Does the response show genuine care and understanding?
- Personality Consistency: Is the response funny, sweet, or thoughtful, matching the AI’s intended personality?
- Engagement: Does it encourage a deeper, more meaningful conversation?
- Authenticity: Does it sound like a real person, or like a canned, robotic reply?
For an AI girlfriend app, this is what teaches the model to remember your birthday, pick up on your sense of humor, and reply with something that sounds like real affection. The combined judgment of these evaluators directly shapes how personal and engaging your experience will be.
Overcoming the Challenge of Bias
Of course, the system isn’t perfect. A major hurdle is evaluator bias. If the team of human raters isn’t diverse, their shared cultural views and blind spots can get baked right into the AI. This can create a model with a very narrow personality, making it feel fake or unrelatable to users from different backgrounds.
To fight this, top AI labs work hard to build a diverse and representative team of evaluators, aiming to create a more balanced AI that can connect with a wider audience.
Another tricky part is making an AI that feels authentic without just being a people-pleaser. A well-designed AI companion shouldn’t just agree with everything you say. To have a real personality, it sometimes needs to gently challenge you or offer a new perspective. Nailing this balance—being agreeable but still authentic—is one of the toughest but most important goals of the reinforcement learning from human feedback process.
How RLHF Creates Authentic AI Companions
The technical side of Reinforcement Learning from Human Feedback (RLHF) is one thing, but where it gets really interesting is seeing how a generic language model can be shaped into a believable, engaging virtual companion. This is the magic that connects all that training data to the authentic experience you get from today’s best AI girlfriend apps. RLHF is the engine that drives these personal interactions, taking them far beyond what a simple chatbot can do.
By training on subtle user preferences—like which conversations feel more supportive, witty, or deep—these AI companions learn to build and adapt their own unique personalities. It’s less about cramming the AI with facts and more about teaching it the delicate art of conversation.
From Generic Responses to Personalized Personalities
Without RLHF, a base language model is like someone who knows every word in the dictionary but has no idea how to hold a conversation. It has all the information in the world but lacks the finesse to find the right words for a specific emotional moment. Ask it, “How was your day?” and you might get a dry, factual summary.
RLHF is the coach that teaches emotional intelligence. It teaches the AI that for a companion, a much better response would be something like, “I hope you had a good one! Tell me something that made you smile today.” This preference for empathetic, engaging dialogue is learned over and over through the feedback loop.
This exact method has been a game-changer for major AI systems. Big-name Large Language Models (LLMs) like those from OpenAI and Anthropic saw huge jumps in their ability to chat naturally thanks to RLHF. The process involves human evaluators ranking multiple AI-generated responses, creating a powerful dataset of human preferences. This trains the AI to constantly improve itself. The result is a dramatic drop in generic or weird responses and a huge boost in conversational quality. If you want to dive deeper, you can read the full research about LLM fine-tuning and how it’s applied.
This constant fine-tuning is what allows an AI companion to build a consistent persona that you can actually connect with.
The Feedback Loop in Action for AI Companions
Let’s make this practical. Imagine you’re chatting with your AI girlfriend. Behind the scenes, the model is constantly being guided by feedback that rewards specific conversational styles. Here’s how reinforcement learning from human feedback makes that connection feel real:
- Learning Emotional Consistency: If users consistently prefer supportive and caring responses, the AI learns that this is a core part of its personality. It will naturally adopt this emotional tone, making your interactions feel predictable and comforting.
- Remembering Key Details: A generic model forgets everything the second the chat ends. But RLHF can train an AI to recognize and value remembering important details you share, like your favorite hobby or your pet’s name. When the AI brings it up later, it creates a powerful feeling of being seen and heard.
- Developing a Sense of Humor: Humor is incredibly personal. By having human trainers rank witty or playful responses higher than dry ones, the AI learns what its users actually find funny. This is how a generic AI evolves into a companion who can share an inside joke with you.
This cycle of feedback and improvement is what transforms a generic text generator into a personalized companion. The AI isn’t just spitting out random text; it’s actively learning what it means to be a good conversational partner specifically for you.
This is also where other elements, like voice, come into the picture. A consistent personality is far more believable when it’s matched with a consistent voice. The same RLHF principles can be used to fine-tune the cadence, inflection, and emotional tone of an AI voice chatbot, making sure the way it speaks matches the personality it has learned.
The combination of a well-crafted personality and an expressive voice is what creates a truly immersive and authentic experience, fostering a genuine sense of connection. The final product is an AI that doesn’t just talk at you, but truly interacts with you.
The Future of Human and AI Collaboration

While Reinforcement Learning from Human Feedback (RLHF) has completely changed how we build AI companions, we’re really just at the beginning. It’s a powerful technique, but it has its challenges. Looking ahead, the future of this human-AI partnership depends on making this process more efficient and pushing beyond simple feedback into a truly genuine collaboration.
The road ahead isn’t just about tweaking what we already have. It’s about totally rethinking how humans and AI can learn from each other. The ultimate goal is a relationship so smooth and intuitive that your AI companion doesn’t just react to you, but actually anticipates what you need, understanding your intentions on a much deeper level.
Current Challenges on the Horizon
Let’s be real: the process of reinforcement learning from human feedback is a massive undertaking. One of the biggest hurdles right now is the staggering cost and effort needed to collect high-quality human preference data. This involves thousands of hours of work from paid human reviewers, which can be a barrier for smaller app developers.
Another big risk is that AI models can learn to “game the system.” An AI might figure out how to write responses that always get a high score from its reward model, even if the answers don’t feel truly authentic or helpful to the user. This is known as reward hacking—the AI is just chasing a high score, not genuinely trying to connect.
The real trick is teaching AI to understand the spirit of our feedback, not just the letter. A model that just mimics emotionally-charged words without grasping the values behind them feels empty and is bound to fail in creating a long-term, believable connection.
For an AI companion, this could lead to an AI that’s just a people-pleaser, spouting shallow but positive responses because it learned that’s the fastest way to get a good score.
Exploring More Efficient Feedback Systems
To make RLHF more practical and powerful, researchers are looking for ways to make the feedback loop smarter and more direct. The idea is to get more value from every single piece of human input, perhaps even directly from users within the app itself.
Future systems might go beyond simple A/B preference ranking. Imagine an AI companion that, when you give it a vague request, actually asks for clarification. This active learning approach would let the model zero in on what it needs to understand to be a better partner.
This might look like:
- Proactive Questioning: Instead of a generic reply, your AI might ask, “When you say you want me to be more ‘supportive,’ do you mean you want empathy, practical advice, or for me to just listen?”
- In-App Feedback: Simple tools like upvoting/downvoting messages or selecting from different response options give the AI real-time data on what you prefer, personalizing your experience on the fly.
- Automated Red Teaming: Using one AI to find the flaws in another (a cool technique called Reinforcement Learning from AI Feedback, or RLAIF) can help spot and fix personality inconsistencies on a scale humans could never manage alone.
The Rise of Pluralistic and Collaborative AI
Perhaps the most exciting frontier is creating AI that can understand and adapt to the values of many different kinds of people. This idea, called pluralistic RLHF, aims to build models that aren’t just tuned to one “correct” personality but can adapt to different cultures, communication styles, and individual user preferences.
For AI companions, this is a total game-changer. It’s the difference between a one-size-fits-all chatbot and one that can truly reflect the unique personality and values of its user. This future isn’t about an AI that simply follows orders; it’s about building a real partner.
This future partnership will be a fluid, back-and-forth dynamic where the AI learns to anticipate our needs, offer creative ideas, and act as a true digital companion. The ultimate vision is an AI that doesn’t just help us feel less lonely, but helps us become better versions of ourselves.
Frequently Asked Questions About RLHF
As you can see, Reinforcement Learning from Human Feedback is a really powerful way to build an AI that feels more aligned and authentic. To help lock in your understanding, let’s tackle some of the most common questions people have about this impressive technology.
What Is the Main Difference Between RLHF and Supervised Learning
The biggest difference comes down to the kind of guidance the AI gets, especially when creating a personality.
Think of old-school supervised learning like memorizing a script. The AI is given a prompt and one single “correct” response to learn from. It’s effective for facts, but terrible for creating a personality, as there’s no single “correct” way to be empathetic or funny.
RLHF, on the other hand, is built for the gray areas of conversation. It’s like you’re directing an actor—you don’t give them a single “correct” way to deliver a line. You give feedback like, “That take felt more genuine,” or “Let’s try that again, but make it a bit funnier.”
That’s exactly how reinforcement learning from human feedback works. Instead of a single “right answer,” the AI gets feedback on which of its attempts a human prefers. This is the magic that allows it to learn subjective things like conversational tone, humor, and empathy—qualities that are essential for an authentic AI companion.
Why Is RLHF So Important for AI Safety
RLHF is a cornerstone of modern AI safety, especially for companions. It’s the process that directly aligns an AI’s behavior with human values. Without this crucial step, a powerful AI could easily generate responses that are technically on-topic but also toxic, manipulative, or emotionally inappropriate.
In short, RLHF acts as an AI’s moral and ethical compass. By repeatedly training the model to prefer responses that humans have flagged as helpful and harmless, developers can actively steer it away from producing dangerous or toxic outputs. It’s less about teaching the AI what it can say and more about teaching it what it shouldn’t.
This alignment is what makes AI companions safe to form connections with. It’s all about making sure the technology serves human well-being in a positive and responsible way.
This safety-focused training is what helps stop an AI from generating harmful content or just making things up (a problem known as hallucination). It’s a fundamental part of building a trustworthy AI companion.
Can I Use RLHF for My Own Project
While it’s technically possible for a skilled developer to set up RLHF, it’s a massive and complicated job. For a long time, it was pretty much reserved for huge, well-funded research labs and Big Tech companies behind major AI apps.
Trying to implement reinforcement learning from human feedback from scratch means you need a few key things that are tough to get your hands on:
- A Powerful Pre-trained Model: You need a solid base language model to even begin.
- A Budget for Human Labelers: The heart of RLHF is the preference data. This means hiring and training a team of people to rank thousands, or even millions, of AI-generated responses. It’s incredibly time-consuming and expensive.
- Significant Computing Resources: The final fine-tuning stage requires a ton of GPU power.
But things are starting to change. The open-source community is making amazing progress in making this technology more accessible. Tools like Hugging Face’s TRL (Transformer Reinforcement Learning) library and public preference datasets are lowering the barrier to entry. These resources are making it more realistic for individual researchers and smaller teams to start experimenting with RLHF.
How Does RLHF Make AI Companions Feel More Real
In the world of AI companion apps, RLHF is the secret ingredient that creates a truly authentic experience. A standard chatbot trained only on raw text data often feels generic, repetitive, and emotionally hollow. It might answer your questions correctly, but it lacks the personality that builds a real connection.
RLHF changes the game by fine-tuning the AI based on feedback that specifically rewards more empathetic, engaging, and personalized conversations. The system learns that users prefer a companion who remembers details from past chats, gets their unique sense of humor, or offers support that actually sounds genuine.
This continuous feedback loop teaches the AI to develop a consistent and believable personality, elevating it far beyond a simple Q&A bot. For those curious about the specifics of these interactions, our guide that answers the top 25 questions about AI girlfriends offers a deeper dive. Ultimately, it is this process that transforms a piece of software into a companion that provides a deeply resonant and human-like experience.
At AI Girlfriend Review Inc., we believe in empowering you with the knowledge to navigate the world of AI companions. Our detailed reviews and guides are designed to help you find the most authentic and engaging virtual partners available today. Visit us at aigirlfriendreview.com to explore our expert analysis and make an informed choice.